|
I am a first-year Ph.D. student at University of Minnesota, advised by Prof. Yang Zhao. My research interests are in computer architecture, VLSI and LLM, with a focus on hardware-algorithm co-design and LLM-empowered hardware design. I received B.Eng. in Microelectronics Science and Engineering from Fudan University, and collaborated with Prof. Lingli Wang in Reconfigurable Accelerator design such as CGRA. |

Email: qin00162@umn.edu |
Research InterestsMy current research interests lie in the intersection of efficient computer architecture and emerging AI algorithms, mainly for two directions: Algorithm-Hardware Co-Design for AI Workloads: I conduct algorithm-hardware co-design to develop efficient hardware accelerators tailored for advanced AI workloads, such as Hyperdimensional Computing (HDC) and 3D Gaussian Splatting SLAM (3DGS-SLAM). These efforts enhance their performance, efficiency and resilience. Automatic AI Agent System for Hardware Design: I explore automated AI agent systems to assist advanced hardware design, such as 2.5D integration. By leveraging AI-driven methodologies, my work aims to improve design automation, reduce human effort, and enhance the overall efficiency of the hardware design process. |
PrePrint (*: Equal Contributions)
HDLxGraph: Bridging Large Language Models and HDL Repositories via HDL Graph Databases
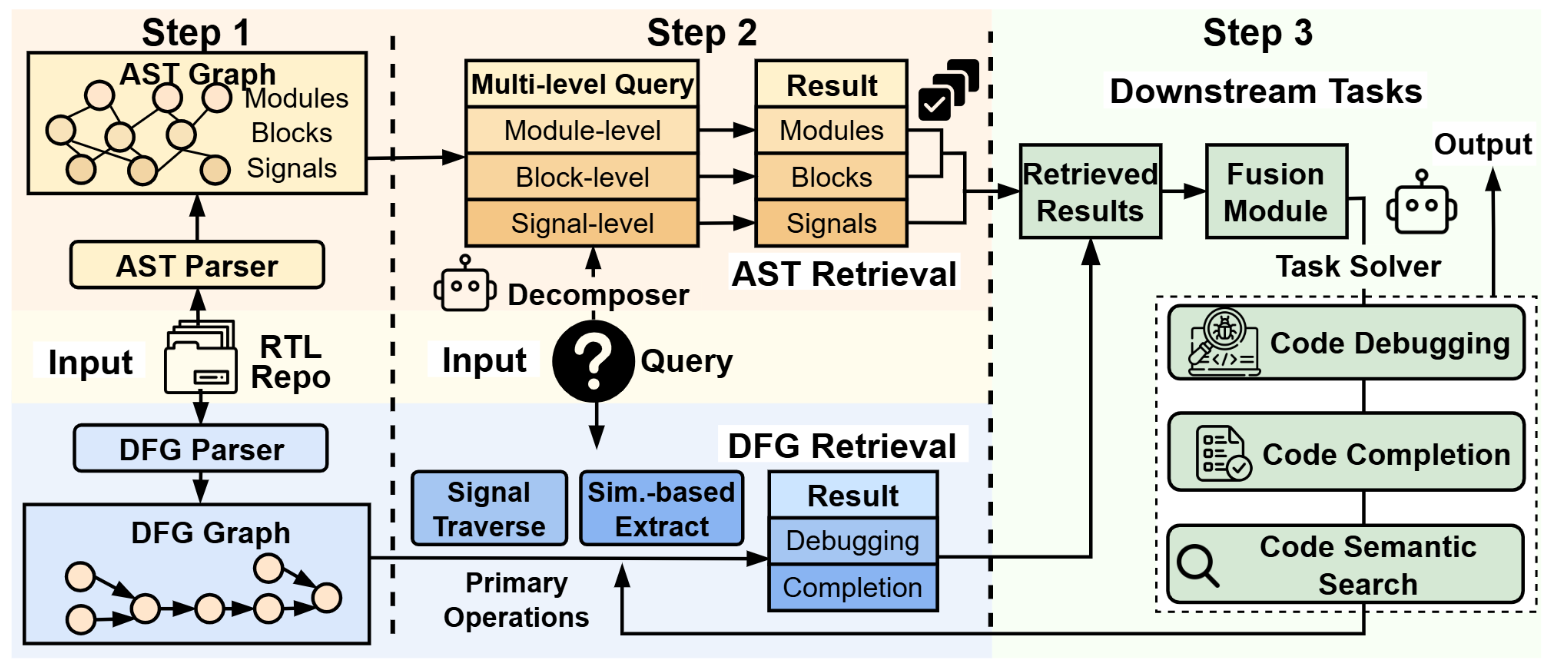
Large Language Models (LLMs) performance in real-world, repository-level HDL projects with thousands or even tens of thousands of code lines is hindered. To this end, we propose HDLxGraph, a novel framework that integrates Graph Retrieval Augmented Generation (Graph RAG) with LLMs, introducing HDL-specific graph representations by incorporating Abstract Syntax Trees (ASTs) and Data Flow Graphs (DFGs) to capture both code graph view and hardware graph view. Additionally, to address the lack of comprehensive HDL search benchmarks, we introduce HDLSearch, a multi-granularity evaluation dataset derived from real-world repository-level projects.
Publication (*: Equal Contributions)
MAHL: Multi-Agent LLM-Guided Hierarchical Chiplet Design with Adaptive Debugging
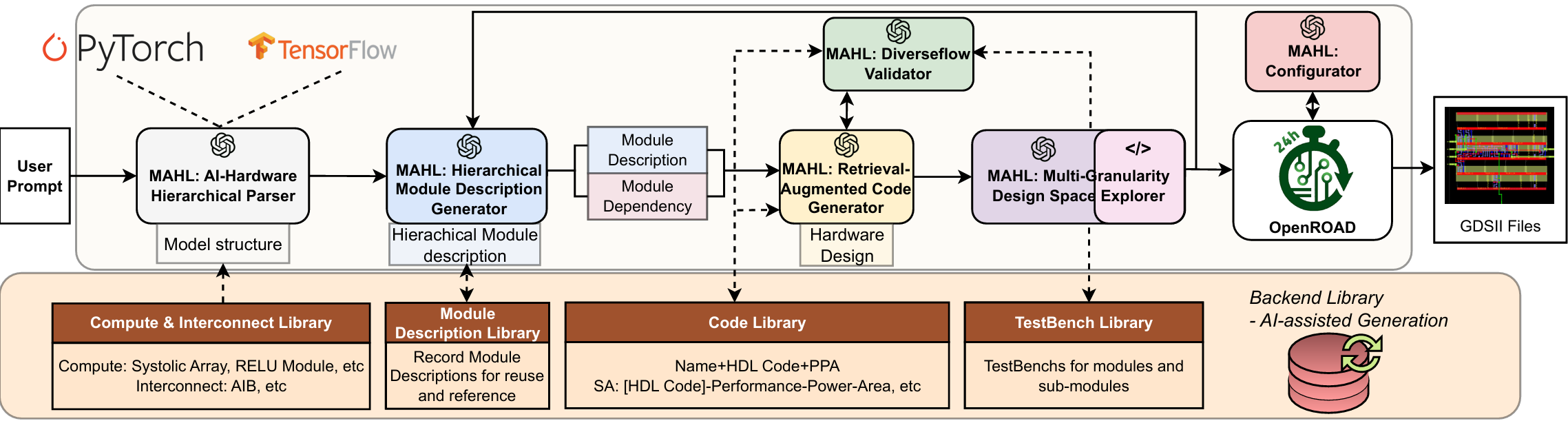
International Conference on Computer Aided Design (ICCAD), 2025 (To appear)
We propose MAHL, a hierarchical LLM-based chiplet design generation framework that features six agents which collaboratively enable AI algorithm-hardware mapping, including hierarchical description generation, retrieval-augmented code generation, diverseflow-based validation, and multi-granularity design space exploration. These components together enhance the efficient generation of chiplet design with optimized Power, Performance and Area (PPA).
HiVeGen -- Hierarchical LLM-based Verilog Generation for Scalable Chip Design
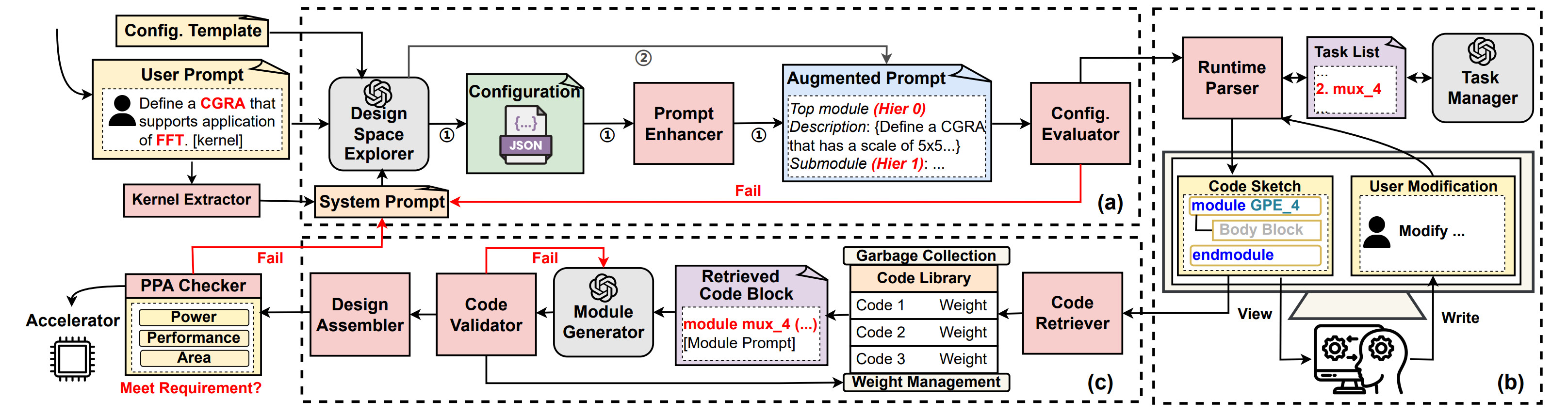
IEEE International Conference on LLM-Aided Design (ICLAD) Best Paper Award, 2025 (To appear)
We propose HiVeGen, a hierarchical LLM-based Verilog generation framework that decomposes generation tasks into LLM-manageable hierarchical submodules. HiVeGen further harnesses the advantages of such hierarchical structures by integrating automatic Design Space Exploration (DSE) into hierarchy-aware prompt generation, introducing weight-based retrieval to enhance code reuse, and enabling real-time human-computer interaction to lower error-correction cost, significantly improving the quality of generated designs.
CGRA-HD: An Efficient Reconfigurable Accelerator for Hyperdimensional Computing
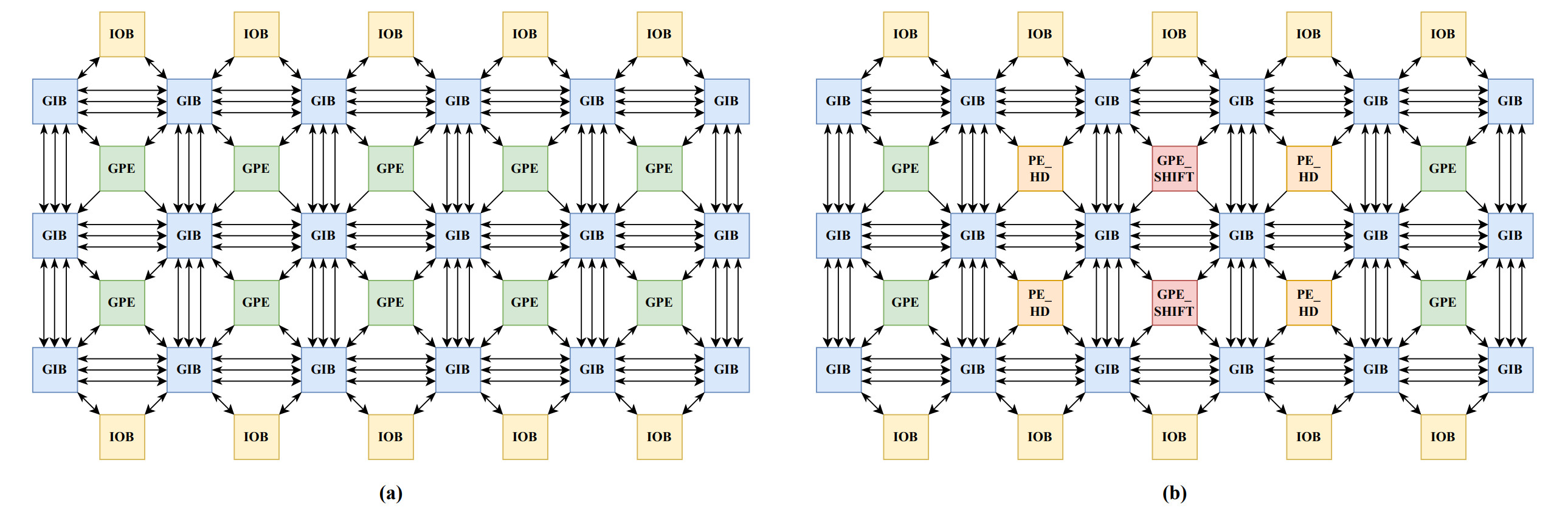
International Conference on Field Programmable Technology (FPT), 2024 (To appear)
We present CGRA-HD, a coarse-grained reconfigurable architecture (CGRA) for accelerating the HDC algorithm. By analyzing the frequent operations and general sub-graphs, we explore the specialized Processing Element (PE) design for HDC to realize efficient acceleration. The specialized PE and the general one constitute a CGRA-HD array and have been integrated into a state-of-the-art RISC-V+CGRA SoC. Our evaluation shows that CGRA-HD greatly improves HDC performance over CPUs with decreased area and power consumption compared to the general CGRA.